How to Display the Progress Bar in Linux Commands?
The previous article has explained how to display progress in a process, but unfortunately, this application is limited to displaying the copy and move process. This article will explain how to display a progress that not only displays the copy and move process, but can also display the backup process and restore a database.
Problem
How to display the progress bar in Linux commands?
Solution
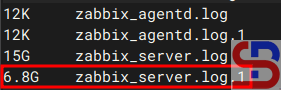
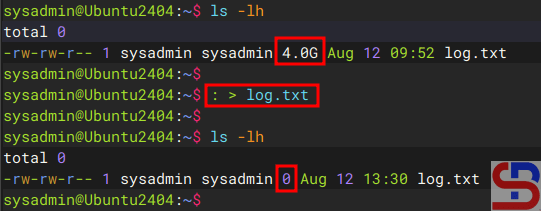
By default, Linux commands do not display a progress bar, so you don’t know when the process is complete, like in the image below:

Therefore, Andrew Wood, An Experienced Unix Sysadmin, created an application to display a progress bar named Pipe Viewer or PV. To install the application, use the command below:
RockyLinux/AlmaLinux/CentOS
yum install epel-release
yum install pv
Ubuntu/Debian
sudo apt update
sudo apt install pv
OpenSUSE
sudo zypper install pv
If you want to install pv applications in addition to the operating system shown above, you can go to this page. Here are some methods when using the pv application:
A. Copy
1. Copy the file
Use the format below to copy the file:
pv file1 > /folder/filename
So, if you want to copy an instances.sql to the /tmp folder, use the command below:
pv instances.sql > /tmp/instance.sql
2. Copy more than one file
If you want to copy more than one file to the folder, use the format below:
tar cf - file1 file2 file3 | pv | tar xf - -C /folder
Here is the command to copy more than one file to the /tmp folder
tar cf - babel.sql babel.sql.gz babel.sql.tar.gz | pv | tar xf - -C /tmp
3. Copy the folder
If you want to copy the folder, use the format below:
tar cf - folder_name/ | pv | tar xf - -C /folder
If you want to copy the example folder to the /tmp folder, use the command below:
tar cf - example/ | pv | tar xf - -C /tmp
4. Copy more than one folder
If you want to copy more than one folder, use the format below:
tar cf - folder1/ folder2/ | pv | tar xf - -C /folder
So, if you want to copy more than one folder to the /tmp directory, use the command below:
tar cf - example/ test-project/ | pv | tar xf - -C /tmp
B. Move
If you want to use the move command on the PV application, then you can actually use the command to copy number 1, but add the command && rm -rf file1/folder1 behind it.
1. Move the file
So, if you want to move an instances.sql to the /tmp folder, use the command below:
pv instances.sql > /tmp/instance.sql && rm -rf instances.sql 
2. Move more than one file
If you want to move some files to the /tmp folder, use the command below:
tar cf - babel.sql babel.sql.gz babel.sql.tar.gz | pv | tar xf - -C /tmp && rm -rf babel.sql babel.sql.gz babel.sql.tar.gz 
3. Move the folder
If you want to move a folder to the /tmp folder, use the command below:
tar cf - example/ | pv | tar xf - -C /tmp && rm -rf example/
4. Move more than one folder
If you want to move some folders to the /tmp folder, use the command below:
tar cf - example/ test-project/ | pv | tar xf - -C /tmp && rm -rf example/ test-project/ 
C. Compress
1. Using gz
Use the format below to run the gz command in pv application:
pv filename | gzip > filename.gz
For example, you want to compress babel.sql using gz, so use the command below:
pv babel.sql | gzip > babel.sql.gz
2. Using tar
Use the format below to run the tar command in pv application:
tar cf - filename | pv | gzip > filename.tar.gz
For example, you want to compress babel.sql using tar, use the command below:
tar cf - babel.sql | pv | gzip > babel.sql.tar.gz
3. Using bz2
Use the format below to run the tar command in pv application:
pv filename | bzip2 > filename.bz2
For example, you want to compress babel.sql using bz2, use the command below:
pv babel.sql | bzip2 > babel.sql.bz2
4. Using zip
Use the format below to run the tar command in pv application:
pv filename | zip filename.zip -q -
For example, you want to compress babel.sql using bz2, use the command below:
pv babel.sql | zip babel.sql.zip -q -
D. Extract
1. Using gunzip
Use the format below to extract the gz compression in pv application:
pv filename.gz | gunzip > filename
For example, you want to extract babel.sql.gz, so use the command below:
pv babel.sql.gz | gunzip > babel.sql
2. Using tar.gz
Use the format below to extract the gz compression in pv application:
pv filename.tar.gz | tar zxf -
For example, you want to extract babel.sql.tar.gz, so use the command below:
pv babel.sql.tar.gz | tar xzf -
3. Using bunzip2
Use the format below to extract the bz2 compression in pv application:
pv filename.sql.bz2 | bunzip2 > filename.sql
For example, you want to extract babel.sql.bz2, so use the command below:
pv babel.sql.bz2 | bunzip2 > babel.sql
4. Using unzip
Use the format below to extract the zip compression in pv application:
unzip filename.zip | pv
For example, you want to extract babel.sql.zip, so use the command below:
unzip babel.sql.zip | pv
E. Backup DB
If you use MariaDB, you can use the commands below:
1. Without compressing the database
Use the format below to back up the database without compression in pv application:
mariadb-dump -u username -p dbname | pv > dbname.sql
So, use the command below to back up the database without compression in pv application:
mariadb-dump -uroot -p babel | pv > babel.sql
2. Back up the database using gz
Use the format below to back up the database using gz compression in pv application:
mariadb-dump -u username -p dbname | pv | gzip > dbname.sql.gz
Use the command below to back up the database using gz compression in pv application:
mariadb-dump -uroot -p babel | pv | gzip > babel.sql.gz
3. Backup the database using bz2
Use the format below to back up the database using bz2 compression in pv application:
mariadb-dump -u username -p dbname | pv | bzip2 > dbname.sql.bz2
Use the command below to back up the database using bz2 compression in pv application:
mysqldump -uroot -p babel | pv | bzip2 > babel.sql.bz2
F. Restore DB
If you use MariaDB, you can use the commands below:
1. Restore the database without compression
Use the format below to restore the database without compression in pv application:
pv backup_file.sql | mariadb -u username -p
So, use the command below to restore the database without compression in pv application:
pv babel.sql | mariadb -uroot -p
2. Restore the database with gz compression
Use the format below to restore the database using gz compression in pv application:
pv backup_file.gz | gunzip | mysql -u username -p
Use the command below to restore the database using gz compression in pv application:
pv babel.sql.gz | gunzip | mariadb -uroot -p 
3. Restore the database with bz2 compression
Use the format below to restore the database using bz2 compression in pv application:
pv backup_file.sql.bz2 | mariadb -u username -p
Use the command below to restore the database using bz2 compression in pv application:
pv babel.sql.bz2 | bunzip2 | mariadb -uroot -p babel
Note
If you are using a MySQL database, then you can use the commands in point E to back up the database and the commands in point F to restore the database by changing the mariadb-dump command to mysqldump and changing the mariadb command to mysql.
References
superuser.com
howtogeek.com
dba.stackexchange.com
tecmint.com
catonmat.net